

Qu'est-ce que le budget de crawl (ou budget d'exploration) ?
Imaginez Googlebot, le robot de Google, comme un explorateur infatigable qui parcourt le web pour découvrir de nouvelles pages et mettre à jour celles qu'il connaît déjà. La vérité c'est que cet explorateur n'a ni un temps illimité ni des ressources infinies. C'est là qu'intervient le budget de crawl, aussi appelé crawl budget.
Pour faire simple, le budget de crawl est le nombre de pages que Googlebot est prêt à explorer sur votre site web pendant une période donnée. C'est comme si Google allouait une certaine quantité d'énergie ou de "crédits d'exploration" à votre site. Plus votre site est grand ou important, plus ce budget peut être élevé.
Pourquoi le budget de crawl est important pour le SEO ?
Le budget de crawl intervient au tout début du processus d'optimisation.
Si Google ne crawle pas votre contenu il n'y a aucune chance de voir ce dernier être indexé puis remonter ensuite sur Google.
Une mauvaise gestion de votre budget de crawl peut avoir des conséquences directes et néfastes sur votre visibilité SEO :
- Retards de mise à jour : Vos nouvelles publications ou les mises à jour de contenu existant mettront plus de temps à être prises en compte par Google, ce qui peut vous faire perdre en pertinence et en actualité.
- Pages non indexées : Si Googlebot épuise son budget sur des pages sans intérêt (comme des pages d'erreur ou des doublons), il ne pourra pas découvrir et indexer vos pages importantes, même si elles sont de grande qualité
- Perte de visibilité : Moins de pages indexées ou des pages indexées tardivement signifient moins d'opportunités d'apparaître dans les résultats de recherche et donc moins de trafic organique potentiel.
En somme, un budget de crawl bien géré assure une meilleure indexation de votre contenu, une réactivité accrue de Google face à vos mises à jour et, in fine, une amélioration significative de votre performance SEO.
Comment analyser son budget de crawl ?
Le budget de crawl est une information que l'on peut déduire des logs de passage de Googlebot ou que l'on peut retrouver dans la Google Search Console.
Comment analyser son budget de crawl via la Google Search Console ?
Il existe un rapport dans la Google Search Console, souvent méconnu et boudé par les SEO mais qui a toute son utilité dans le cadre de l'analyse de logs, il faut dire qu'il est bien caché.
Il est situé dans "Paramètres" > "Statistiques d'exploration"
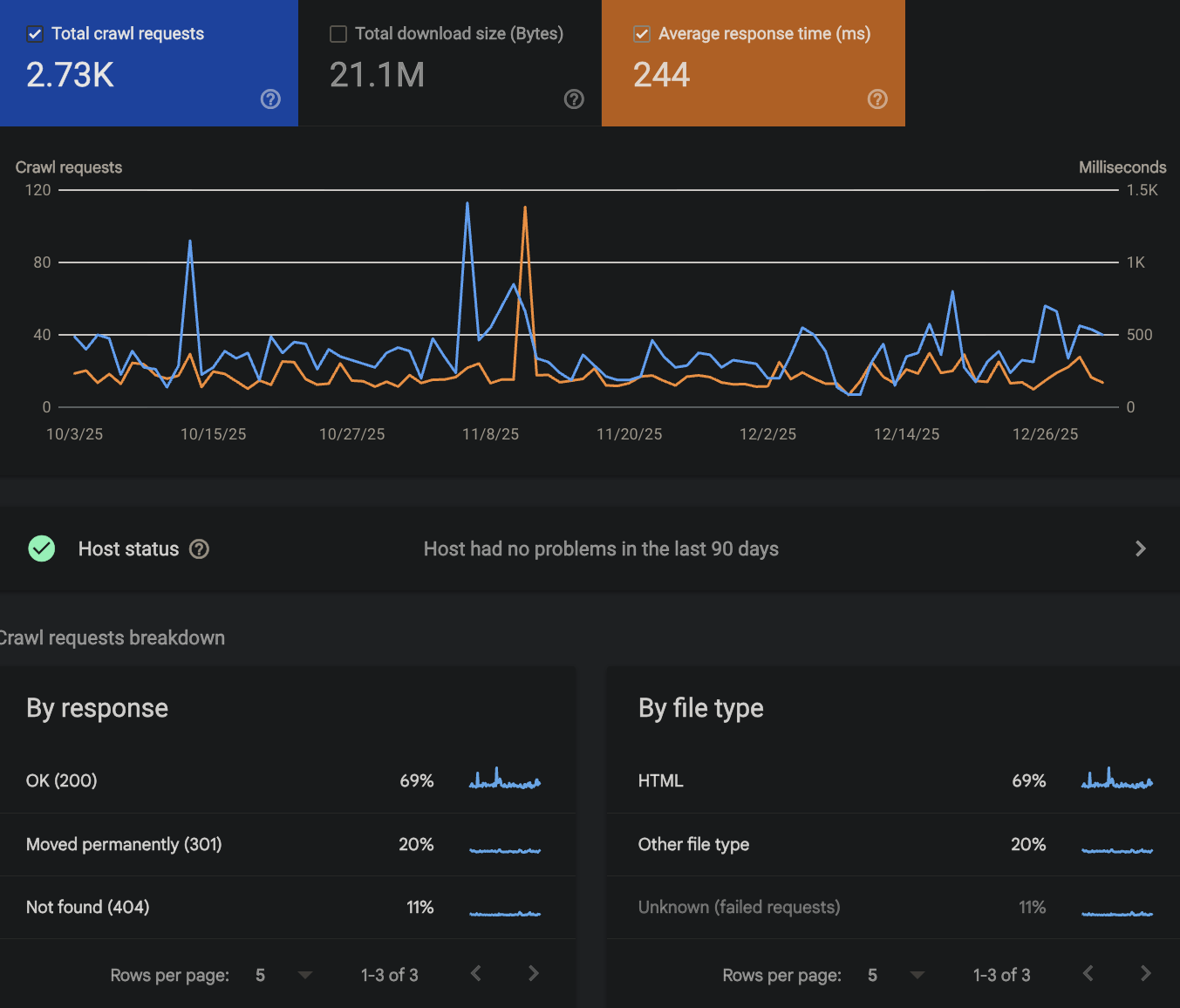
Comment analyser son budget de crawl via les logs de passage (access.log) ?
👀 Cette est option est bien plus compliquée à mettre en oeuvre que l'analyse via la Google Search Console, dans un premier temps je vous recommande vivement de tirer vos premières conclusions des l'analyse de la Google Search Console
Les logs d'accès sont des fichiers texte dans lequel une ligne représente le passage d'un bot sur votre site. Il existe d'autres types de logs pour les erreurs par exemple mais ils sont moins utiles pour le SEO.
Ces fichiers textes sont géré et déposés par le serveur à chaque demande de ressource. Ainsi avec l'ensemble de ces logs on peut retracer l'activité des crawlers pour investiguer sur le budget de crawl et la perception que se font les crawlers du site.
Pour se fournir ces fichiers il faut vous rapprocher de votre équipe technique (développeur sur des petits sites, équipe IT / infra sur des plus gros site).
Une fois ces fichiers en votre possession il faut les retraiter afin de pouvoir les exploiter de façon plus structurées (filtrage, tris, data visualization...). Les outils les plus communs sont Screaming Frog Logs, ELK ou via des outils de crawl cloudés type OnCrawl ou Botify.
Que faut-il regarder pour analyser le budget de crawl ?
- Le volume global de demandes de crawl rapporté au nombre des pages utiles de mon site. L'analyse est simple : est-ce que Google crawle fréquemment toutes vos pages utiles ? Prenez le nombre de pages utiles (via le rapport d'indexation ou un crawl) que vous rapporter au nombre de visites de Googlebot (sur les pages), si Google crawle plus que le nombre de pages c'est bon signe et souvent j'arrête l'analyse à ce stade : j'en déduis qu'il n'y a pas de problèmes et que je peux analyser d'autres sujets pour essayer de trouver une action plus impactante.
- La tendance : est-ce que la courbe monte ou descend ? Est-ce que cette tendance suite une logique ? Par exemple à l'approche des soldes, suite à la publication de nouvelles pages ou au rafraîchissement de votre catalogue produit.
- Les corrélations : j'aime bien comparer la courbe du temps de réponse et celle des demandes de visites, elles sont souvent corrélées. Lorsque le temps de réponse chute, Google met moins de temps à explorer le site et est souvent plus tenté de venir visiter le site.
- La décomposition : par statut, par template, par type de ressource ou de user agent. A ce stade je rentre dans le détail pour voir si j'arrive à tirer d'autres conclusions : est-ce que Google crawle en préférence certains types de pages ? Est-ce qu'il les crawl en suivant une logique ? Il y a des centaines de cas différents que je ne peux pas vous énumérer ici mais la logique est simple : il faut fouiller pour affiner l'analyse.
👀 Les crawlers n'obéissent pas à une logique de parcours et crawlent les pages de façon séquentielle et stateless. En d'autres termes ils sont amnésiques et ne fonctionnent pas avec une logique parcours. Ainsi ce n'est pas parce qu'une page A est connectée à une page B qui nécessairement le bot va "passer" par la page B avant A
Comment optimiser votre budget de crawl ?
1. Améliorez la vitesse de votre site
La vitesse de site est un facteur crucial. Un site rapide permet aux robots d'exploration de Google de parcourir plus de pages en moins de temps, utilisant ainsi leur budget de crawl de manière plus efficace. Un site lent, en revanche, "frustre" Googlebot et le pousse à quitter votre site prématurément.
Il y a plusieurs définitions de ce qu'est un site rapide ou lent. Dans le cas du crawl pour moi la métrique la plus pertinente c'est le TTFB (Time To First Byte). Ce chiffre un peu barbare désigne simplement le temps que mets le serveur à renvoyer le premier octet de sa réponse : pour faire simple, sa rapidité brute.
2. Orientez les bots sur les pages utiles via le /robots.txt
Le fichier /robots.txt donne des instructions claires pour les robots d'exploration. Il leur indique quelles parties de votre site ils peuvent ou ne peuvent pas explorer. Une bonne gestion de ce fichier est essentielle pour l'optimisation crawl.
- Bloquez les pages sans valeur SEO : empêchez les crawlers d'explorer des pages comme les pages d'administration, les pages de remerciement, les paniers d'achat vides ou les résultats de recherche internes.
- A l'inverse, évitez de bloquer des pages importantes : assurez-vous que vos pages clés, celles que vous voulez voir indexées, ne sont pas bloquées par erreur.
L'objectif est de diriger Googlebot vers le contenu le plus pertinent et de lui éviter de gaspiller son attention sur des URL inutiles.
3. Donnez aux moteurs de recherche de l'utile : éliminez la duplication et les pages de faible valeur
Le contenu dupliqué ou de faible qualité est un véritable fardeau pour votre budget de crawl. Les crawlers perdent du temps à explorer et à analyser des pages qui n'apportent pas de valeur ajoutée à l'utilisateur final.
- Supprimez ou fusionnez les pages redondantes : Identifiez les pages avec un contenu très similaire et décidez de les supprimer (404, 410, 301), de les améliorer ou de les fusionner.
- Améliorez la qualité de votre contenu existant : Assurez-vous que chaque page offre une valeur unique et pertinente à vos utilisateurs.
- Utilisez les balises canoniques : Pour les cas où le contenu dupliqué est inévitable (par exemple, différentes versions d'un produit), utilisez la balise rel="canonical" pour indiquer à Google quelle est la version préférée.

Discussions en lien